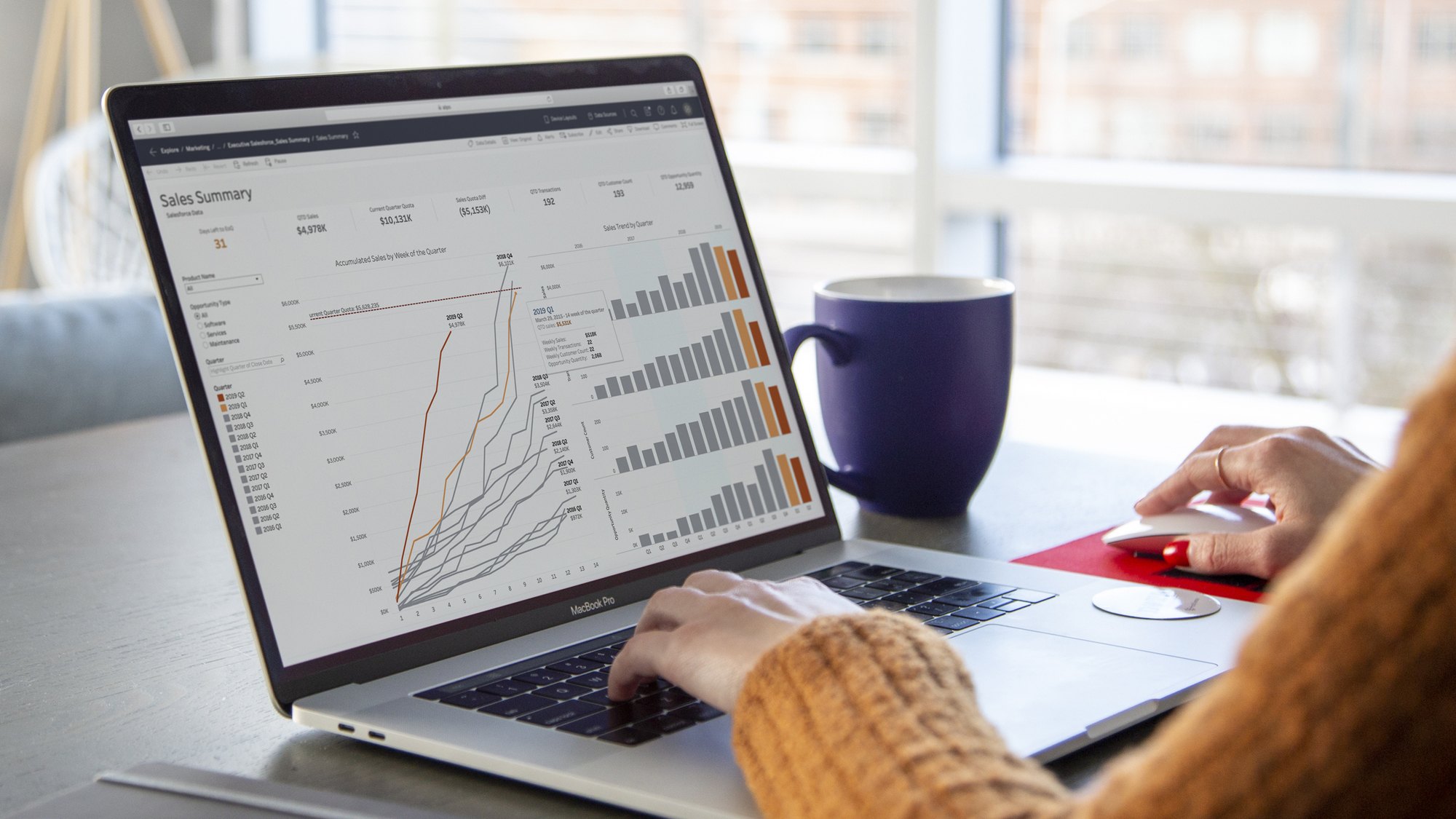
Module 1: Introduction to Data Science and R
- 1.1 What is Data Science?
- Overview of Data Science and its applications
- Data Science vs Machine Learning vs AI
- The role of a Data Scientist
- 1.2 Introduction to R Programming
- Why use R for Data Science?
- Installing R and RStudio
- Basic R Syntax: Variables, Data Types, Operators
- R Data Structures: Vectors, Lists, Matrices, Data Frames, and Factors
- 1.3 Introduction to R Libraries for Data Science
- Overview of essential R libraries:
dplyr,ggplot2,tidyr,caret,lubridate
- Overview of essential R libraries:
Module 2: Data Import, Cleaning, and Preprocessing
- 2.1 Data Import and Export
- Importing data from CSV, Excel, SQL, and web scraping
- Exporting data to different formats (CSV, Excel, etc.)
- 2.2 Data Cleaning and Transformation
- Handling missing data (NA values)
- Data Transformation with
dplyr(select, filter, mutate, group_by, summarize) - Data wrangling with
tidyr(gather, spread, separate, unite) - String manipulation with
stringr - Working with dates using
lubridate
- 2.3 Data Preprocessing for Machine Learning
- Scaling and Normalization
- Encoding Categorical Data (One-hot encoding)
- Feature Engineering
Module 3: Data Visualization in R
- 3.1 Introduction to Data Visualization
- Importance of Visualization in Data Science
- Basic Visualization Principles
- 3.2 Basic Plotting with
ggplot2- Grammar of Graphics (Understanding ggplot2 structure)
- Scatter plots, bar plots, histograms, and box plots
- 3.3 Advanced Visualization with
ggplot2- Customizing plots (labels, themes, and colors)
- Faceting and multi-panel plots
- Plotting time-series data
- 3.4 Interactive Visualizations
- Interactive Plots with
plotlyandshiny
- Interactive Plots with
Module 4: Exploratory Data Analysis (EDA)
- 4.1 Introduction to EDA
- Importance of EDA in the Data Science Workflow
- Summary Statistics: Mean, Median, Mode, Standard Deviation
- Distribution of Data (histograms, density plots)
- 4.2 Univariate and Bivariate Analysis
- Visualizing distributions and relationships using
ggplot2 - Identifying correlations using correlation matrices
- Box plots and violin plots for comparing distributions
- Visualizing distributions and relationships using
- 4.3 Outlier Detection and Handling
- Identifying outliers using box plots, scatter plots, and Z-scores
- Handling outliers through removal or transformation
- 4.4 Data Profiling and Summary
- Descriptive statistics using
summary()andstr() - Profiling data with the
skimrpackage
- Descriptive statistics using
Module 5: Statistical Analysis
- 5.1 Introduction to Statistics for Data Science
- Descriptive Statistics: Mean, Median, Mode, Variance, Standard Deviation
- Probability Distributions (Normal, Binomial, Poisson)
- Central Limit Theorem
- 5.2 Hypothesis Testing
- T-tests, Chi-Square Tests, ANOVA
- p-values, Confidence Intervals, and Significance Levels
- Assumptions in Statistical Tests
- 5.3 Correlation and Regression
- Pearson Correlation Coefficient
- Linear Regression (Simple and Multiple)
- Interpreting Model Coefficients and Residuals
- Logistic Regression for Binary Classification
- Regularization: Lasso and Ridge
Module 6: Machine Learning with R
- 6.1 Introduction to Machine Learning in R
- Overview of Supervised vs Unsupervised Learning
- Preparing data for Machine Learning
- Using the
caretpackage for Model Training
- 6.2 Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees and Random Forests
- Support Vector Machines (SVM)
- K-Nearest Neighbors (KNN)
- 6.3 Unsupervised Learning Algorithms
- K-Means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- DBSCAN and Other Clustering Methods
- 6.4 Model Evaluation and Tuning
- Cross-validation
- Hyperparameter Tuning using Grid Search
- Evaluating Model Performance (Accuracy, Precision, Recall, F1-Score)
- ROC Curve and AUC
Module 7: Advanced Topics in Machine Learning
- 7.1 Ensemble Methods
- Bagging, Boosting, and Stacking
- Random Forests and Gradient Boosting Machines (GBM)
- XGBoost, LightGBM, and CatBoost
- 7.2 Model Interpretation and Explainability
- Feature Importance using Random Forest and XGBoost
- SHAP Values and LIME for Model Explainability
- 7.3 Time Series Analysis and Forecasting
- Introduction to Time Series Data
- Decomposition of Time Series (Trend, Seasonality, Residuals)
- ARIMA Models and Forecasting
- Exponential Smoothing (Holt-Winters)
- 7.4 Natural Language Processing (NLP)
- Text Preprocessing: Tokenization, Lemmatization, Stopword Removal
- Sentiment Analysis and Text Classification
- Word Embeddings (Word2Vec, GloVe)
- Topic Modeling with Latent Dirichlet Allocation (LDA)
Module 8: Data Science in Practice
- 8.1 Working with Big Data
- Introduction to Big Data Concepts
- Using
data.tablefor large datasets - Parallel Processing in R
- Introduction to Hadoop and Spark with R (via
sparklyr)
- 8.2 Model Deployment
- Deploying models using
plumberfor APIs - Packaging Models with
docker - Deploying Shiny Apps for Interactive Dashboards
- Deploying models using
- 8.3 Building Data Pipelines
- Extracting, Transforming, and Loading (ETL)
- Automating Data Pipelines with
drakeandtargets